
Die Anforderungen an E-Commerce-Systeme sind in den letzten Jahren massiv gestiegen. Dazu gehören einerseits die Wünsche der Kunden und Nutzer, andererseits möchten auch die Entwickler und Administratoren nicht mehr wie in den 1990er-Jahren arbeiten. Um eine moderne E-Commerce-Plattform aufzubauen, gibt es mehrere Wege. Einer ist der über sogenannte Build Pipelines.
Was früher üblich war, ist heutzutage ein No-Go
Die E-Commerce-Systeme befinden sich in einem Wandel. Früher war es in Ordnung, seinen Onlineshop auf einem kleinen Server zu betreiben. Veränderungen fanden nur gelegentlich statt, und wenn es welche gab, wurden diese direkt auf den Server geladen. Nicht selten kam es zu „Operationen am offenen Herzen“, bei denen die Entwickler den Quellcode des Onlineshops direkt auf dem Produktivsystem veränderten. Das war pragmatisch und ging schnell. Doch es sorgte auch für allerlei Fehler.
Heutzutage sieht die Vorgehensweise – zum Glück – größtenteils anders aus. Wächst der Onlineshop oder wird von Anfang an ein großes E-Commerce-Projekt geplant, reicht es nicht mehr aus, lediglich einen Server zu mieten. Stattdessen kommen E-Commerce-Landschaften zum Einsatz. Technisch spricht man hier von einem Clusterbetrieb. Ein solches System besteht aus mehreren Servern. Es garantiert eine leichte Skalierung, schnelle Verfügbarkeit und rasante Performance. Es ist den Endkunden – im B2C wie auch im B2B – nicht mehr zumutbar, dass sie Fehlermeldungen sehen oder dass es zu Ausfällen kommt. Stattdessen gilt die Prämisse: Der Kunde möchte immer und überall schnell und bequem einkaufen. Um solch einen Clusterbetrieb zu ermöglichen, müssen zahlreiche Dinge beachtet werden. Die Build Pipelines helfen dabei, eine moderne E-Commerce-Landschaft zu betreiben.
Was ist eine Build Pipeline?
Eine Build Pipeline kann man sich wie eine Fertigungsstraße vorstellen. Wie in einer Fabrik werden schrittweise gewisse Aufgaben durchgeführt, bis am Ende ein fertiges Produkt entsteht. Wer eine Build Pipeline für ein E-Commerce-Projekt umsetzt, muss wie in der Industrie verschiedene Abschnitte durchwandern, um schlussendlich ein fertiges, lauffähiges und performantes Ergebnis zu erhalten.
Welche und wie viele Abschnitte (Stages) existieren, hängt von der Art der Software bzw. des E-Commerce-Systems und dem geplanten Endzustand ab. Jede Stage besteht aus mindestens einer Aufgabe. Sind mehrere Aufgaben in einer Stage vorhanden, können diese auf Jobs verteilt werden, welche dann parallel ablaufen. Das spart eine Menge Zeit und sorgt für eine schnelle Produktion. Der Vorteil liegt auf der Hand: Je flotter es ein Ergebnis gibt, desto zügiger kann die E-Commerce-Plattform den Betrieb aufnehmen und Umsatz generieren. Im Grunde ist eine Build Pipeline eine automatisierte Abarbeitung einer Checkliste. Das hat viele Vorteile. Einer ist, dass kein Mensch benötigt wird, der die langweilige Abarbeitung einer Checkliste übernimmt. Außerdem kommt es zu weniger Fehlern als bei einer manuellen Ausführung. Wenn immer wieder das Gleiche zu tun ist, sind Computer gegenüber dem Menschen deutlich im Vorteil.
Ein Praxis-Beispiel für den Einsatz von Build Pipelines
In unserem Beispiel wird ein Onlineshop getestet, Dokumentationen generiert und auf einem Cluster veröffentlicht. Eine Checkliste für derartige Aufgaben fällt ziemlich umfangreich aus. Und mit dem Wachstum des Systems müssen immer mehr Dinge installiert, aktualisiert, geprüft, kopiert, konfiguriert und verwaltet werden. Die Build Pipeline hilft hierbei immens. Sie beginnt mit dem richtigen Setup.
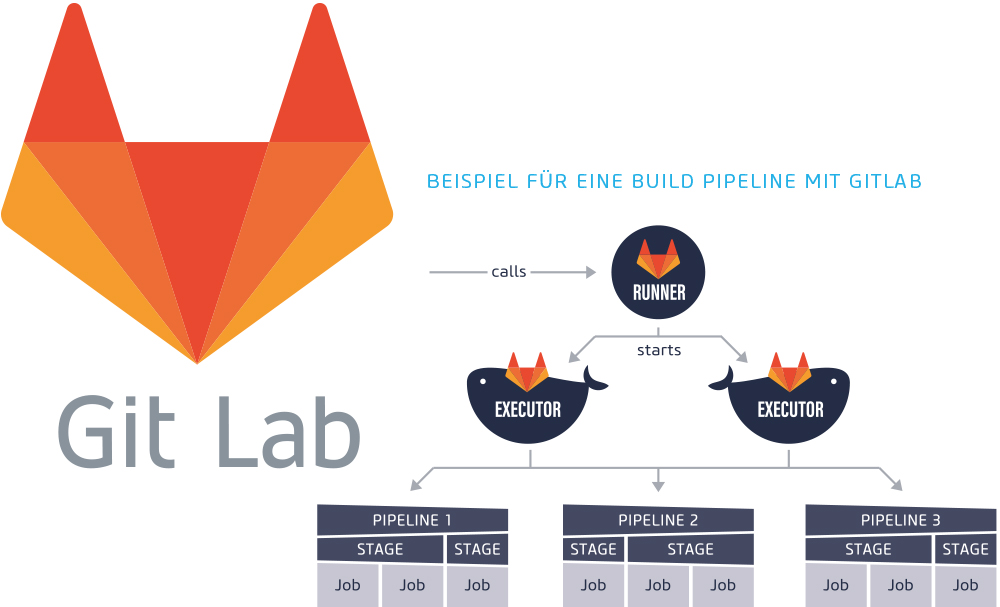
Schritt 1: Setup
Im ersten Schritt wird die E-Commerce-Software inklusive Software-Bibliotheken und Drittanwendungen installiert. Ist alles installiert, geht es weiter zur Qualitätssicherung.
Schritt 2: Qualitätssicherung
Damit die E-Commerce-Software einer definierten Qualität entspricht, muss diese einer Reihe von Tests unterzogen werden. Der einfachste Test prüft den vom Entwickler versionierten Quellcode auf offensichtliche Fehler. Das können beispielsweise syntaktische Fehler sein, die eine Ausführung des Programmcodes nicht zulassen. Auch strukturelle Probleme oder Sicherheitslücken lassen sich mittels solcher Software-Tests aufdecken. Diese können – je nach eingestelltem Level der Qualitätsprüfung – die weitere Verarbeitung in der Build Pipeline stoppen.
Im Idealfall erhält der Entwickler, der den fehlerhaften Quellcode in die Versionsverwaltung eingespielt hat, eine entsprechende Fehlermeldung. Je früher das Entwickler-Team über vorliegende Schwachstellen und Fehler informiert wird, desto einfacher ist die Behebung und Integration der Bugfixes in andere Softwarebereiche – zum Beispiel bei GIT Integration Branches.
Schritt 3: Artefakte erzeugen
Im nächsten Schritt werden Artefakte erzeugt und nach dem Build zur Verfügung gestellt. Das können beispielsweise Dokumentationen, Auswertungen oder Installer sein. In dem beispielhaften E-Commerce-Projekt soll die Build Pipeline aus dem Quellcode und aus bestimmten Dokumentationsdateien jeweils ein gesondertes Handbuch erzeugen, um ein Systemhandbuch mit technischen Inhalten und ein Benutzerhandbuch mit Anleitungen für die Benutzer des Onlineshops zu erhalten. Die technischen Informationen können aus dem übermittelten Quellcode stammen, das Benutzerhandbuch kann mit Sphinx-Doc generiert werden.
Schritt 4: Deployment
Das Deployment (auch Rollout genannt) stellt den Vorgang dar, bei dem die E-Commerce-Software auf die Zielsysteme verteilt wird. Da auf dem Markt eine riesige Anzahl von verschiedenen Hosting-Plattformen und -Technologien existieren, kann das Deployment umfangreich und kompliziert ausfallen. Auch Firmen-Policies haben einen gewaltigen Einfluss auf das Deployment: Einige Firmen schließen beispielsweise Cloud-Anbieter aus, weswegen fertige Standard-Dienste nicht einfach eingesetzt werden können. Das hat zur Folge, dass individuelle Anpassungen am Deployment-Script vorgenommen werden müssen.
Auch Netzwerkeinstellungen wirken sich auf das Rollout aus. Nicht selten kommt es vor, dass Firewalls ausgehende Verbindungen blockieren. Damit fällt die Möglichkeit weg, auf dem Zielsystem Anweisungen auszuführen, die Informationen nachladen. Am einfachsten ist es, wenn die Verbindung nur in eine Richtung aufgebaut werden muss, um die Daten auf das Zielsystem zu übertragen.
Werden Container für das Deployment eingesetzt, ist der Vorgang sehr einfach. Es müssen nur die Container verteilt werden. Wird auf dem Zielsystem eine Software zur Cloud-Orchestrierung verwendet, kann man einen Container auch auf mehrere Ziel-Server automatisch verteilen. Cloud-Anbieter wie Amazon, Google oder Microsoft bieten bereits fertige Dienste, um die Container zu verteilen, zu skalieren und zu betreiben.
Eine gute Build/Deployment Pipeline ermöglicht es, dass nur eine qualitätsgesicherte Anwendung auf den Zielsystemen landet. Sinnvollerweise sollte das Deployment vorher auf einem Staging- System durchgeführt werden, um manuelle oder automatisierte Tests der Umgebung durchzuführen. Passt alles, kann dasselbe Artefakt (Container, Tarball, etc.) auf das Produktivsystem gebracht werden. Damit ist gewährleistet, dass auch die im Staging-System getestete Version der Software auf das Produktivsystem gelangt.
Mit einem automatisierten Deployment-Prozess kann die Anzahl der Software-Aktualisierungen deutlich zunehmen. Das freut die Entwickler, da sie keine Checklisten mehr abarbeiten müssen und zudem leicht die Möglichkeit haben, häufig kleinere Releases zu veröffentlichen. Hierdurch sinkt die Fehleranfälligkeit. Und bei Problemen lässt sich bequem auf die vorherige Version zurückrollen.
Tools für Build Pipelines
Da Build Pipelines zunehmend beliebter werden, wachsen die entsprechenden Tools wie Pilze aus dem Boden. Die bekanntesten Vertreter sind sicherlich Jenkins und Gitlab, die auf einem eigenen Server betrieben werden können. Jenkins punktet aufgrund seiner weiten Verbreitung mit einer sehr großen Auswahl von verfügbaren Erweiterungen. Damit lassen sich Funktionen wie eine Container-Unterstützung nachrüsten. Eigene Erweiterungen lassen sich mit Java realisieren.
Gitlab ist relativ neu, das Tool erhält in einem rasanten Tempo ständig neue Funktionen, und es wurde für die Unterstützung von Containern oder Orchestrierung-Tools wie Kubernetes ausgelegt. Gitlab setzt auf die Skriptsprache Ruby für die Entwicklung.
Anbieter wie Jetbrains und Atlassian, die für Tools wie Jira oder IntelliJ bekannt sind, mischen mit Bamboo und TeamCity auf dem Markt der Build Pipeline Tools munter mit. Zusätzlich zu den On-Premises-Systemen gibt es auch eine große Auswahl von Anbietern, die ihre Tools als Software-on-demand offerieren. Bekannte Vertreter sind Buildbot, Drone, Concourse, CircleCI, Codeship, Codefresh, Bitbucket und Travis.
Jedes Tool besitzt seine ganz eigenen Vor- und Nachteile. Ist man als Entwickler im .NET-Umfeld tätig, bietet sich TeamCity an. Unternehmen, die bereits das Atlassian Tool-Stack nutzen, sollten eher zu Bamboo greifen, da sich das ganz komfortabel integrieren lässt. Und für Unterstützer des Open-Source-Gedankens bietet sich Gitlab an. Die eierlegende Wollmilchsau in Sachen Build Pipelines gibt es nicht – somit kommt man um eine Evaluierung nicht umhin.
Fazit
Build Pipelines sind für jedes Unternehmen, das mit Software entwickelt, besonders wichtig, da sie für eine starke Reduktion von Fehlern sorgen und somit das Team entlasten. Im E-Commerce-Umfeld lassen sich damit schneller neue Funktionen oder Fehlerbeseitigungen veröffentlichen. Das steigert den Umsatz. Warum also mit der Einführung warten?
Bilder: netz98, freepik








