
Erfolgreicher E-Commerce benötigt eine solide, vollständige Datenbasis für die angebotenen Produkte. Doch gerade im B2B-Segment sind umfassende bessere Produktdaten eine große Herausforderung. Im Blogbeitrag stellen wir eine innovative, KI-gestützte Lösung von netz98 zur automatischen Datenanreicherung vor und präsentieren anhand eines Praxisbeispiels ihren konkreten Einsatz.
Bessere Daten: Voraussetzung für funktionierenden E-Commerce – und sein größtes Problem
Produktdaten sind unerlässlich für fast alle Funktionen eines jeden Webshops. Sie spielen eine Rolle bei Suche und Kategorie-Listings, der Präsentation von Produkten und sind meist auch für den gesamten Checkout-Prozess von Bedeutung. Ohne ordentlich gepflegte Produktattribute kann es keine aussagekräftigen Produktvergleiche geben, Suchmaschinen-Marketing (SEO, SEA) sind deutlich weniger wirksam und Innovationen rücken in weite Ferne.
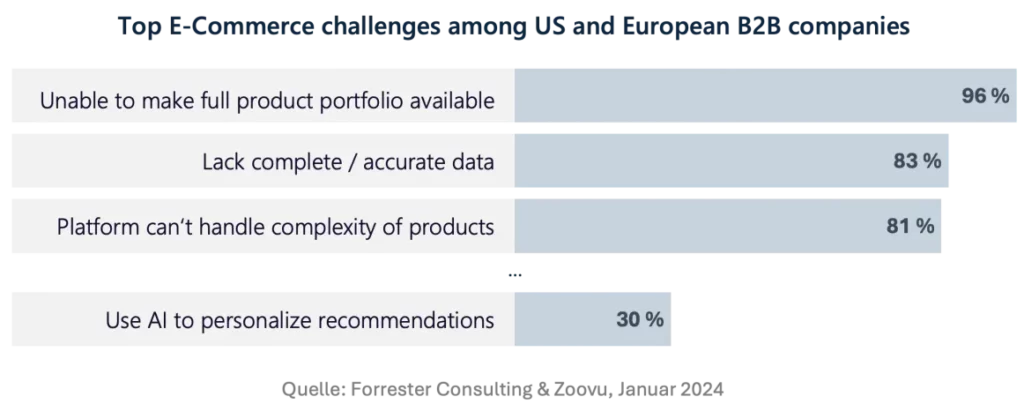
Eine aktuelle Umfrage des Beratungsinstituts Forrester Consulting vom Januar 2024 zeigt jedoch, dass fast kein Unternehmen im B2B-Sektor in der Lage ist, den vollständigen Produktkatalog online verfügbar zu machen. Das Hauptproblem liegt hierbei insbesondere in einer unvollständigen oder inkorrekten Datengrundlage. Das in der Umfrage ebenfalls genannte Problem einer zu komplexen Produktstruktur, ist in der Regel für Magento-basierte Projekte kein Thema – sein flexibles Datenmodell erlaubt nahezu beliebige Konfigurationen.
netz98 hat das Problem unbefriedigender Produktdaten ebenfalls erkannt und in den vergangenen Monaten Ansätze entwickelt, um bessere Produktdaten für Onlineshops zu erhalten. Im Kern stehen hierbei unterschiedliche KI-Modelle (Künstliche Intelligenz), gepaart mit konventionellen Ansätzen wie der altbewährten OCR-Technologie zur Texterkennung. Das von uns umgesetzte Data-Framework ist für ganz unterschiedliche und beliebig komplexe Anwendungsfälle geeignet.
Grundlegende Datenverarbeitung durch die netz98-Lösung mit KI
Am Anfang der Verarbeitungskette („Pipeline“) steht die Zusammenführung aller eingehenden Daten: das können Produktbilder, Datenblätter und Handbücher im PDF-Format oder technische Zeichnungen in beliebigen Grafikformaten sein. Diese werden durch unser flexibles System eingelesen und vorbereitet, indem z.B. der Textinhalt einer Grafik per OCR (Optical Character Recognition) ausgelesen und verarbeitbar gemacht wird.
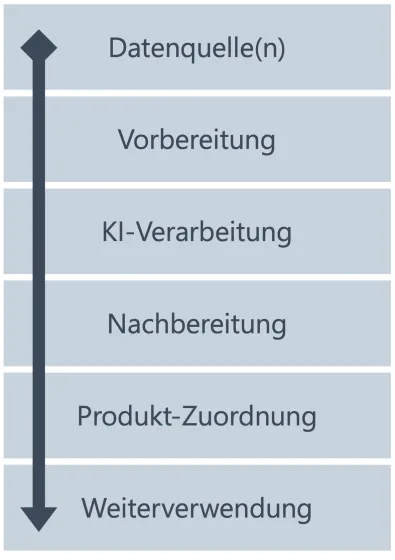
Im nächsten Schritt werden die eingehenden Daten durch geeignete und jeweils individuell zusammengestellte KI-Modelle verarbeitet. Dabei sind zahlreiche Möglichkeiten vorhanden, z.B.
- datengetriebene Systeme zum Auslesen technischer Kennwerte
- große Sprachmodelle (LLM) zur zuverlässigen Erzeugung hochwertiger Texte
- mehrsprachige Modelle für eine hochwertige Textübersetzung
Nach der KI-Verarbeitung müssen die erzeugten Daten unter Umständen noch nachbearbeitet werden, um z.B. die relevanten Informationen herauszufiltern oder nicht benötigte Formatierungen zu entfernen. Anschließend wird das Resultat dem Produkt zugeordnet und unterscheidet sich nicht mehr von manuell gepflegten Datensätzen. Sie stehen somit der Filterung, Suche, Anzeige etc. zur Verfügung.
Diese Pipeline ist mit Absicht sehr abstrakt gehalten, um möglichst vielen Branchen und ihren jeweils individuellen Anwendungsfällen gerecht zu werden. Im nächsten Abschnitt zeigen wir, wie diese Pipeline in einem ganz praktischen Anwendungsfall bessere Produktdaten geliefert hat.
Use Case: Umfangreiche Auswertung von Produktdatenblättern
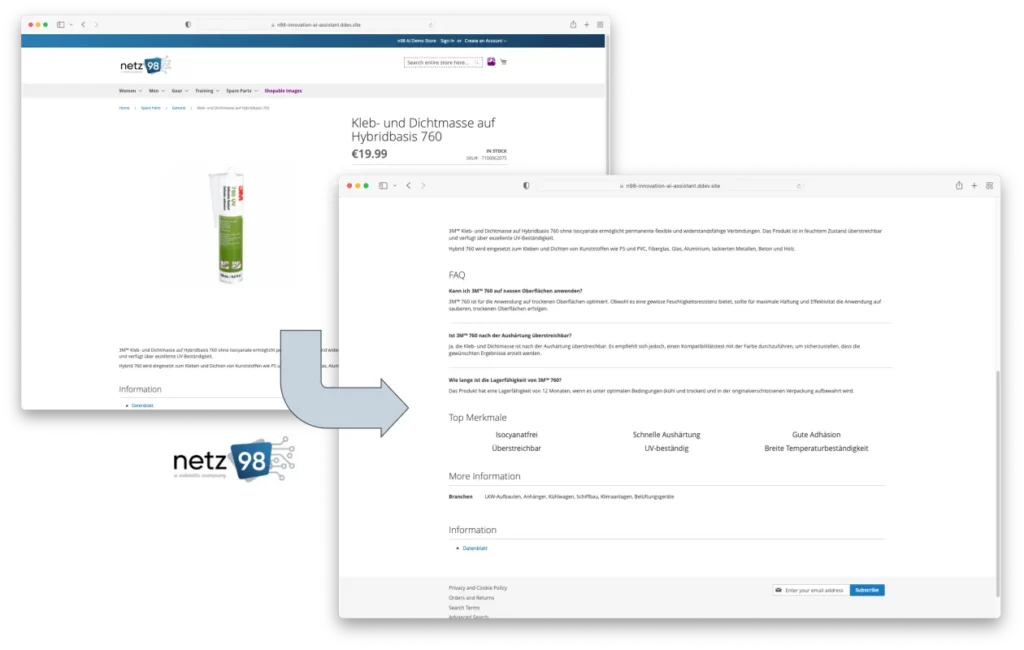
In einem Webshop werden unterschiedliche Kleb- und Dichtstoffe angeboten, für die jeweils einige wenige Basisinformationen bereitstehen: Produktname, ein generischer Beschreibungstext, eine Abbildung sowie das Datenblatt im PDF-Format. Sucht der Kunde nun das für ihn passende Produkt, ist das mit einem hohen Rechercheaufwand verbunden: Sofern der Produktname nicht schon alle notwendigen Details verrät, muss in der Regel das Datenblatt für weitere Informationen heruntergeladen, geöffnet und mühsam gelesen werden. Hier dürfte der Kunde schnell frustriert sein und ggf. auf einen alternativen Webshop ausweichen.
Um diesem typischen Problem begegnen zu können, wurde durch den Shop-Betreiber entschieden, die vorhandene Datenbasis in Form der Datenblätter möglichst umfassend auszuwerten und in die Shopping-Funktion zu integrieren. So konnten mit Hilfe der von uns aufgesetzten Pipeline unter anderem folgende Produktattribute zuverlässig befüllt werden:
- Industrien und Branchen, für die das Produkt relevant ist
- Zentrale Produktmerkmale und USPs
- Zuordnung zu weiteren Kategorien
- SEO-optimierte Beschreibungstexte
- Typische Fragen und Antworten für Benutzer (FAQs)
Nach der automatischen Verarbeitung durch das Data-Framework von netz98, wurde die Qualität der Customer Journey deutlich gesteigert: Der Kunde findet wesentlich schneller den gesuchten Artikel, da ihm nun eine sinnvolle Kategoriestruktur sowie eine leistungsfähige Filterung zur Verfügung stehen. Er kann auf einen Blick die wichtigsten Produktmerkmale erkennen und so schnell zum gewünschten Produkt und somit auch zum Kaufabschluss gelangen.
Der Prozess zur Datenanreicherung dauert pro Produkt durchschnittlich ein bis zwei Minuten. Bei einer großen Artikelanzahl ist dies zwar durchaus ein Faktor, im Vergleich zum menschlichen Aufwand jedoch nicht nur deutlich schneller, sondern natürlich auch entsprechend kostengünstiger.
Datenverarbeitung: vollautomatisch, integriert und sicher – für bessere Produktdaten
Nach der initialen Einrichtung der Pipeline muss diese in der Regel einige Male feinjustiert werden. Anschließend werden die Verarbeitungsschritte aber vollständig automatisiert abgearbeitet. Abgesehen von einer losen Überwachung des Vorgangs fallen keine manuellen Aufwände an. Typischerweise wird die KI-Pipeline über Nacht ausgeführt, sodass störende Auswirkungen auf das Benutzer-Frontend minimiert sind.
Bei hoch dynamischen Systemen gibt es auch Möglichkeiten, die Daten auf einem getrennten System vorzubereiten und dann auf einen Schlag auszuspielen. Der Prozess muss je Produkt nur einmal durchgeführt werden – das spart Zeit und Kosten für die Ausführung der beteiligten KI-Dienste.
Möglicherweise bestehenden Vorbehalten zum Datenschutz und Unternehmensrichtlinien in Bezug auf Intellectual Property stellt die netz98-Lösung den Einsatz lokaler Modelle entgegen: Diese werden in geschlossenen Umgebungen ausgeführt, sodass keinerlei Daten nach außen gelangen. In jedem Fall evaluieren wir die für den jeweiligen, konkreten Anwendungsfall benötigte Infrastruktur gemeinsam, um allen Bedenken und Richtlinien Rechnung tragen zu können.
Flexible Lösung für (fast) alle Datenprobleme
Das Problem unvollständiger, falscher oder inkonsistenter Produktdaten ist weitverbreitet und branchenunabhängig bei vielen Plattformen zu beobachten. Gleichzeitig sind bessere Produktdaten für sämtliche Aspekte des Online-Handels unerlässlich. Je umfassender die Daten desto größer der Vorteil gegenüber dem Wettbewerb.
War die Pflege von Produktdaten bislang überwiegend Handarbeit, so bietet die von netz98 entwickelte Lösung die Chance, diesen aufwändigen Prozess durch KI-getriebene Lösungen in weiten Teilen zu ersetzen. Dabei ist dieser Weg deutlich schneller, günstiger und häufig auch zuverlässiger. Das von uns entwickelte Framework bietet ein solides Fundament für die Anreicherung von Produktdaten, darüber hinaus aber auch beliebige andere Entitäten: Kundendaten, Kategorien oder individuelle Datenmodelle, die Teil einer individuellen Plattform sein können.
Bilder: iStock, netz98







